

Swarm Learning is a complex concept, but here we explain the structure of our methodology in simpler terms. Make sure to check the video by clicking on the image above! Below, you can find our approach in 5 easy steps:
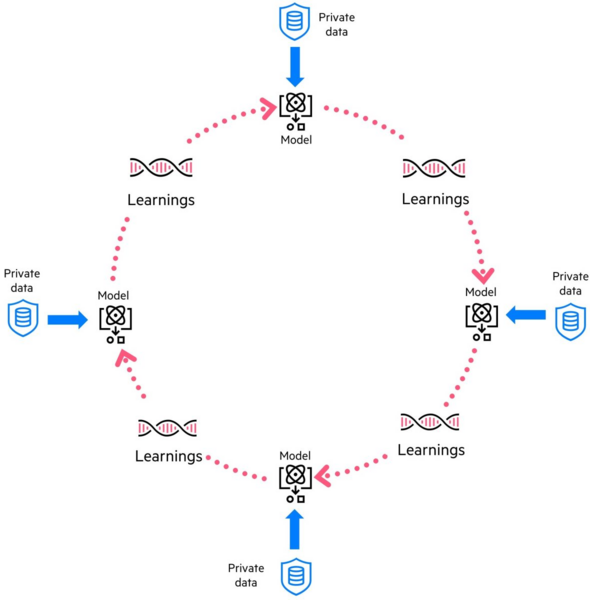
Step 1: Collecting and using data locally
- Each participating group (like hospitals or research labs) collects and cleans up their own data. They use the shared algorithm (model) from the network on this data to learn patterns in their data. Importantly, this data never leaves the group's control, keeping it private and secure.
Step 2: Sharing learning progress
- Instead of sharing their actual data, each group shares the learnings from applying the model to their data in a shared, secure system (like a digital ledger or blockchain). This way, their sensitive information is protected.
Step 3: Combining learnings
- Learnings from all the groups are gathered and combined in the system in a fair way. Security measures also ensure that all partners can contribute in an equitable way and the whole process is transparent and thereby guarantees accuracy and transparency.
Step 4: Updating the learning strategy
- The combined learnings are distributed again to all nodes to continue the learning including this new information. Thereby, all partners are not only contributing their insights but also learn from the other partners.
Step 5: Continuous improvement
- This process repeats over and over, with groups continuously learning from their data, sharing their learnings, combining them, and updating their models. Each cycle makes the models more accurate, benefiting from the collective knowledge without ever sharing the actual data.
Swarm Learning is a decentralized machine learning approach that combines edge computing with blockchain technology to enable collaborative learning across multiple organizations while preserving data privacy. Here's a breakdown of the concept in five sequential steps:
- Data Preparation and Local Training: Collect and preprocess data locally; train local models.
- Parameter Sharing: Share model parameters, not raw data.
- Aggregation and Consensus: Aggregate and integrate parameters from local learnings.
- Model Update and Distribution: Update and distribute the global model to all partners in the network.
- Iterative Learning: Continuously improve model through iterative learning cycles.
A private-permissioned blockchain is used for tracking all transactions necessary for the five steps.
Swarm Learning in detail
Step 1: Data Preparation and Local Training
- Data Collection and Preprocessing
- Each participating node (e.g., hospitals, companies, research institutions) collects and preprocesses its own data locally. This data never leaves the node, ensuring privacy and security.
- Local Model Training
- Each node independently trains a local machine learning model on its own data based on a common algorithm shared in the network. This is done using local computational resources.
Step 2: Model Parameter Sharing
- Parameter Exchange
- Instead of sharing raw data, nodes share model parameters (e.g. weights, gradients). This ensures that sensitive data is not exposed or transferred between nodes.
Step 3: Aggregation and Consensus
- Parameter Aggregation
- Local parameters are aggregated in the network. This can be a simple averaging or achieved by more complex techniques.
- Consensus mechanisms ensure the integrity and reliability of the aggregated model parameters.
Step 4: Model Update and Distribution
- Global Model Update
- The aggregated model parameters (the global model) are distributed back to the participating nodes. Each node integrates these parameters into its local model, enhancing its performance with insights from the broader dataset.
Step 5: Iterative Learning and Improvement
- Iterative Process
- The process is iterative, with nodes continuously training on their local data, sharing updated parameters, and integrating the aggregated global model. Over multiple iterations, the model improves, benefiting from the collaborative learning process without compromising data privacy.
Reference
Warnat-Herresthal, S., Schultze, H., Shastry, K.L. et al. Swarm Learning for decentralized and confidential clinical machine learning. Nature 594, 265–270 (2021). doi.org/10.1038/s41586-021-03583-3