

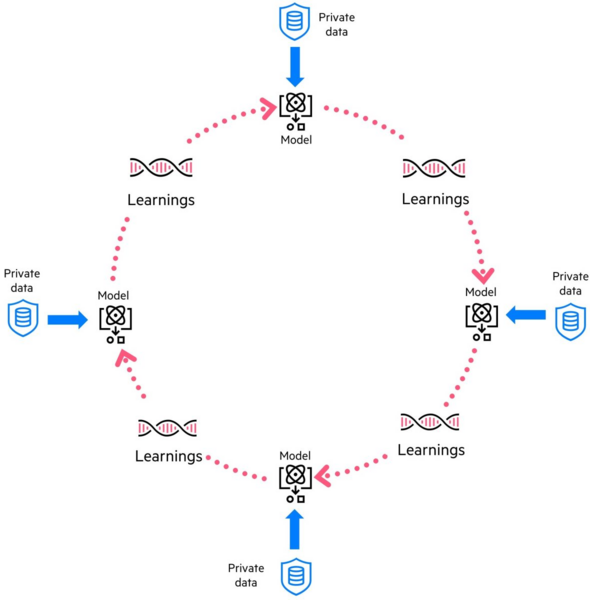
Schwarm Lernen ist ein komplexes Konzept, aber hier erklären wir die Struktur unserer Methodik in einfacheren Worten. Sehen Sie sich unbedingt das Video an, indem Sie auf das Bild oben klicken! Nachfolgend finden Sie unseren Ansatz in 5 einfachen Schritten:
Schritt 1: Daten lokal erfassen und nutzen
- Jede teilnehmende Gruppe (wie Krankenhäuser oder Forschungslabore) sammelt und bereinigt ihre eigenen Daten. Sie verwenden einen unter den Gruppen geteilten Algorithmus (das Modell)für diese Daten, um Muster in ihren Daten zu erkennen. Wichtig ist, dass diese Daten nie die Kontrolle der Gruppe verlassen und somit privat und sicher bleiben.
Schritt 2: Lernfortschritte teilen
- Anstatt ihre eigentlichen Daten zu teilen, teilt jede Gruppe die Erkenntnisse aus der Anwendung des Modells auf ihre Daten in einem gemeinsamen, sicheren System (wie einem digitalen Register oder einer Blockchain). Auf diese Weise sind die vertraulichen Informationen geschützt.
Schritt 3: Erkenntnisse kombinieren
- Erkenntnisse aus allen Gruppen werden im System auf faire Weise gesammelt und kombiniert. Sicherheitsmaßnahmen stellen außerdem sicher, dass alle Partner einen gleichwertigen Beitrag leisten können und der gesamte Prozess transparent ist. Dies garantiert Genauigkeit und Transparenz.
Schritt 4: Aktualisierung der Lernstrategie
- Die kombinierten Erkenntnisse werden erneut an alle Knoten verteilt, um das Lernen unter Berücksichtigung dieser neuen Informationen fortzusetzen. Dadurch tragen alle Partner nicht nur ihre Erkenntnisse bei, sondern lernen auch von den anderen Partnern.
Schritt 5: Kontinuierliche Verbesserung
- Dieser Prozess wiederholt sich immer wieder, wobei die Gruppen kontinuierlich aus ihren Daten lernen, ihre Erkenntnisse teilen, sie kombinieren und ihre Modelle aktualisieren. Jeder Zyklus macht die Modelle präziser und sie profitieren vom kollektiven Wissen, ohne jemals die tatsächlichen Daten zu teilen.
Schwarm Lernen ist ein dezentraler Ansatz für maschinelles Lernen, welcher Edge-Computing mit Blockchain-Technologie kombiniert, um kollaboratives Lernen über mehrere Organisationen hinweg zu ermöglichen und gleichzeitig den Datenschutz zu wahren. Hier ist eine Aufschlüsselung des Konzepts in fünf aufeinanderfolgende Schritten:
- Datenaufbereitung und lokales Trainieren: Lokales sammeln und vorbereiten der Daten; Trainieren lokaler Modelle.
- Teilen der Parameter: Teilen der Modellparameter, nicht der Rohdaten.
- Aggregation und Konsens: Aggregieren und integrieren der Parameter aus lokal gelernten Ergebnissen.
- Modellaktualisierung und -verteilung: Aktualisieren und verteilen des globalen Modells an alle Partner im Netzwerk.
- Iteratives Lernen: Kontinuierliches verbessern des Modells durch iterative Lernzyklen.
Eine Blockchain mit privaten Berechtigungen wird zum Verfolgen aller für die fünf Schritte erforderlichen Transaktionen verwendet.
Schwarm Lernen im Detail
Schritt 1: Datenaufbereitung und lokales Trainieren
- Datenerfassung und Vorbereitung
- Jeder beteiligte Knoten (z.B. Krankenhäuser, Unternehmen, Forschungseinrichtungen) sammelt und bereitet seine eigenen Daten lokal vor. Diese Daten verlassen niemals den Knoten, wodurch Datenschutz und Sicherheit gewährleistet sind.
- Lokales Trainieren des Modell
- Jeder Knoten trainiert unabhängig ein lokales maschinelles Lernmodell anhand seiner eigenen Daten und eines gemeinsamen Algorithmus, der im Netzwerk geteilt wurde. Dies geschieht mithilfe lokaler Rechenressourcen.
Schritt 2: Gemeinsame Nutzung von Modellparametern
- Parameteraustausch
- Anstatt Rohdaten zu teilen, teilen Knoten Modellparameter. Dadurch wird sichergestellt, dass vertrauliche Daten nicht offengelegt oder zwischen Knoten übertragen werden.
Schritt 3: Aggregation und Konsens
- Parameteraggregation
- Lokale Parameter werden im Netzwerk aggregiert. Dies kann durch eine einfache Mittelwertbildung oder durch komplexere Techniken erreicht werden.
- Konsensmechanismen stellen die Integrität und Zuverlässigkeit der aggregierten Modellparameter sicher.
Schritt 4: Modellaktualisierung und -verteilung
- Globales Modell-Update
- Die aggregierten Modellparameter (das globale Modell) werden an die beteiligten Knoten zurückverteilt. Jeder Knoten integriert diese Parameter in sein lokales Modell und verbessert seine Leistung mit Erkenntnissen aus dem umfassenderen Datensatz.
Schritt 5: Iteratives Lernen und Verbesserung
- Iterativer Prozess
- Der Prozess ist iterativ, wobei die Knoten kontinuierlich mit ihren lokalen Daten trainieren, aktualisierte Parameter austauschen und das aggregierte globale Modell integrieren. Im Laufe mehrerer Iterationen verbessert sich das Modell und profitiert vom kollaborativen Lernprozess, ohne den Datenschutz zu beeinträchtigen.
Referenz
Warnat-Herresthal, S., Schultze, H., Shastry, K.L. et al. Swarm Learning for decentralized and confidential clinical machine learning. Nature 594, 265–270 (2021). doi.org/10.1038/s41586-021-03583-3